반응형
자리가 사람을 만든다고 오늘도 어김없이 업무가 주어지고 항상 아무것도 모르는 상태로 실무에 들어가는 느낌이다. 아직까지도 포인터를 사용할 때마다 shared_ptr, unique_ptr을 구글에 검색해 보고 있고, 검색할 때마다 새롭다.
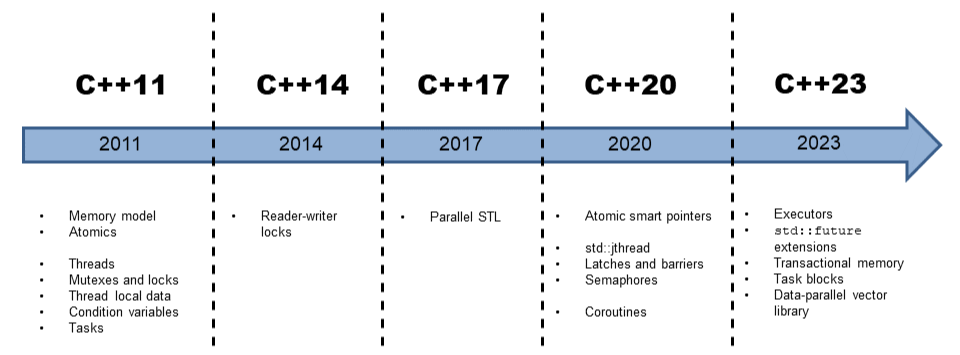
메모리 모델
atomic
- 원자계 연산 : 방해받지 않고 수행될 수 있는 연산
- 연산의 부분 순서 : 순서가 재지정되어야 하는 일련의 연산
원자계 스마트 포인터

std::shared_ptr과std::weak_ptr은 동시성 프로그램에서 개념적 문제를 가짐 : 변형 가능한 데이터를 공유해서 데이터 경쟁에 취약. 리소스에 대한 접근이 원자계임을 보장하지 못함.std::atomic_shared_ptr과std::atomic_weak_ptr
멀티스레딩
스레드 std::thread
- 프로그램 실행의 독립적인 단위
- join : 생성된 스레드가 종료될 때까지 생성자가 기다림
- detach : 생성된 스레드에서 생성자가 분리
- joinable : join이나 detach가 수행되지 않은 상태. joinable 스레드는
std::terminate를 호출하고 종료한다.
공유 데이터
- 둘 이상의 스레드가 동시에 사용/변형하려면 공유 변수에 대한 접근을 조정해야 함.
- data race : 공유 변수를 동시에 읽거나 쓰려고 하는 것
- mutex, lock 으로 해소해야 함.
뮤텍스
- 단 하나의 스레드만 공유 변수에 접근 가능하도록 보장
- 임계 구역을 잠그거나 잠금해제 수행
잠금
- 뮤텍스를 캡슐화
- 뮤텍스의 라이프사이클을 자신에게 바인딩
std::lock_guard,std::unique_lock,std::shared_lock
데이터의 스레드 안전한 초기화
- 공유 데이터가 읽기 전용이면 thread-safe 방식으로 초기화 가능.
- 상수식, 블록 영역의 정적 변수,
std::once_flag플래그가 적용된std::call_once함수 등
스레드 로컬 데이터
- 변수를 thread-local로 선언
조건 변수
- condition variable : 메시지를 통환 스레드 동기화
태스크
std::async에 따라 자동으로 태스크의 라이프사이클을 처리std::promise가 데이터를 데이터 채널에 두면std::future가 값을 가져간다.
실행 정책
- 대부분의 STL 알고리즘을 실행 정책에 따라 병렬로 처리 가능.
- 실행 정책 : 순차
std::seq, 병렬std::par, 츠가 벡터화와 병렬std::par_unseq
래치와 장벽
- counter를 설정하고, 이 값이 0이 될 때까지 스레드를 기다리도록 하는 스레드 동기화 메커니즘
std::latch,std::barrier/std::flex_barrier
코루틴
- 자신의 상태를 유지하면서 중지 및 재개될 수 있는 함수.
co_await,co_yield,co_return,for co_await
트랜잭션 메모리
- db이론의 트랜잭션 개념. 원자성, 일관성, 분리성을 제공하는 액션. 지속성(x)
- 동기화 블록 :
synchronized { }- 원자계 블록 :
atomic_noexcept,atomic_commit,atomic_noexcept
태스크 블록
- fork-join 패러다임 구현
원자계 플래그
std::atomic_flag의 인터페이스는 set하는 메서드만 존재한다.
- 잠김 없는 유일한 원자계다. Non-blocking 알고리즘은 시스템 차원에서 수행된다는 보장이 없으면 잠김 없음이다.
- 더 높은 수준의 스레드 추상화를 위한 빌딩 블록이다.
#include <iostream>
#include <atomic>
#include <thread>
class Spinlock{
std::atomic_flag flag;
public:
Spinlock(): flag(ATOMIC_FLAG_INIT){}
void lock() {
while (flag.test_and_set());
}
void unlock() {
flag.clear();
}
};
Spinlock spin;
void workOnResource() {
spin.lock();
// 공유 리소스
spin.unlock();
}
int main(int argc, const char * argv[]) {
// insert code here...
std::thread t(workOnResource);
std::thread t2(workOnResource);
t.join();
t2.join();
std::cout << "Hello world.\n";
return 0;
}
클래스 템플릿 std::atomic
std::atomic<bool>은 std::atomic_flag와는 true나 false로 명시적인 설정을 할 수 있다는 점에서 다르다.
compare_exchange_strong, compare_exchange_weak 지원
compare_exchange_strong: 원자계 연산 한 번으로 비교하고 교환. 흔히 CAS(Compare And Swap)로 불린다. Non-blocking알고리즘.atomicValue == expected:return true, atomicValue = desiredatomicValue != expected:return false, expected = atomicValuecompare_exchange_weakatomicValue == expected:return false인 경우도 있다.(ABA 문제 : A를 두 번 읽는 동안 B로 바뀌었을 수도 있다는 사실을 간과할 수 있음.)
#include <atomic>
#include <chrono>
#include <iostream>
#include <thread>
#include <vector>
std::vector<int> mySharedWork;
std::atomic<bool> dataReady(false);
void waitingForWork(){
std::cout << "Waiting " << std::endl;
while ( !dataReady.load() ){
std::this_thread::sleep_for(std::chrono::milliseconds(5));
}
mySharedWork[1] = 2;
std::cout << "Work done " << std::endl;
}
void setDataReady(){
mySharedWork = {1, 0, 3};
dataReady = true;
std::cout << "Data prepared" << std::endl;
}
int main(){
std::cout << std::endl;
std::thread t1(waitingForWork);
std::thread t2(setDataReady);
t1.join();
t2.join();
for (auto v: mySharedWork){
std::cout << v << " ";
}
std::cout << "\n\n";
}
std::atomic<T*>
int intArray[5];
std::atomic<int> p(intArray);
p++;
assert(p.load() == &intArray[1]);
p+=1;
assert(p.load() == &intArray[2]);
--p;
assert(p.load() == &intArray[1]);
std::atomic<integral type>
+=,-+,&=,|=,^=fetch_add,fetch_sub,fetch_and,fetch_or,fetch_xor- 곱셈이나 나눗셈, 시프트 연산은 없음.
// 원자계 곱셈
#include <atomic>
#include <iostream>
template <typename T>
T fetch_mult(std::atomic<T>& shared, T mult){
T oldValue = shared.load();
while (!shared.compare_exchange_strong(oldValue, oldValue * mult));
return oldValue;
}
int main(){
std::atomic<int> myInt{5};
std::cout << myInt << std::endl;
fetch_mult(myInt,5);
std::cout << myInt << std::endl;
}
사용자 정의 원자계
- 원자계 타입을 직접 정의할 수도 있다.
- 제한 :
- 모든 기본 클래스 및 비정적 멤버에 대한 대입 연산자 재정의 x
- 가상 메서드나 가상 기본 클래스 x
memcpy/memcmp등 비트 단위의 비교 연산이 가능해야 함.
std::shared_ptr
- 원자계 연산을 적용할 수 있는 유일한 비원자계 데이터 타입.
- 스레드 안전 방식에 따라 reference counter를 늘리거나 줄임. (
std::shared_ptr의 제어 블록이 스레드 안전하기 때문) - 리소스가 딱 한번만 파괴됨.
shared_ptr인스턴스를 여러 스레드에서 동시에 읽기 가능(const 연산으로만 접근 가능)shared_ptr인스턴스들을 여러 스레드에서 동시에 쓸 수 있다.- 스레드 안전 복사 : 복사를 통해 ptr을 바인딩.
std::shared_ptr<int> ptr = std::make_shared<int>(2011);
for (auto i = 0; i < 10; i++) {
std::thread([ptr]{
std::shared_ptr<int> localPtr(ptr);
localPtr = std::make_shared<int>(2014);
}).detach();
}
- 리소스 경쟁 상태 : 레퍼런스로 ptr을 바인딩.
std::shared_ptr<int> ptr = std::make_shared<int>(2011);
for (auto i = 0; i < 10; i++) {
std::thread([&ptr]{
ptr = std::make_shared<int>(2014);
}).detach();
}
- 데이터 경쟁 해결 : 스레드 안전 방식으로 레퍼런스에 의해 바인딩된 ptr을 수정.
std::shared_ptr<int> ptr = std::make_shared<int>(2011);
for (auto i = 0; i < 10; i++) {
std::thread([&ptr]{
std::shared_ptr<int> localPtr(ptr) = std::make_shared<int>(2014);
std::atomic_store(&ptr, localPtr);
}).detach();
}
반응형
'c++' 카테고리의 다른 글
| Xcode14 사용기 (1) - console app (0) | 2022.08.15 |
|---|
